The beauty of the vendor-independent standard OpenCL is that a single kernel language is sufficient to program many different architectures, ranging from dual-core CPUs over Intel's Many Integrated Cores (MIC) architecture to GPUs and even FPGAs. The kernels are just-in-time compiled during the program run, which has several advantages and disadvantages. An incomplete list is as follows:
- Advantage: Binary can be fully optimized for the underlying hardware
- Advantage: High portability
- Disadvantage: Just-in-Time compilation induces overhead
- Disadvantage: No automatic performance portability
Today's blog post is about just-in-time (jit) compilation overhead. Ideally, jit-compilation is infinitely fast. In reality, it is sufficient to keep the jit-compilation time small compared to the overall execution time. But what is 'small'?
Benchmark Setup
Consider simple OpenCL kernels like the following:
__kernel void kernel_1_2(__global float * x) { x[2] = 1; }
The kernel only sets the third entry of the buffer x to 1. Since the kernel is so simple, it is reasonable to expect that a jit-compiler only requires a fraction of a second to compile this kernel.
If you run a more involved OpenCL application, you may need a couple of different kernels. Taking the iterative solvers in ViennaCL as an example, one quickly needs about 10 different kernels for simple setups. More elaborate preconditioners quickly drive up the number to 15 or 20. Each of those kernels is more involved than the one shown above. To mimic a realistic workload, consider the compilation of 64 kernels similar to the one above. By varying the kernel name (hence the _1_2 suffix) and the index used, we make sure that all the kernels are indeed distinct and no caching optimizations in jit-compilers trigger.
How are the 64 kernels compiled? There are several options with OpenCL: One may put all kernels into a single OpenCL program (i.e. compilation unit) and call the jit-compiler only once. At the other hand, one may use on OpenCL program per kernel, resulting in 64 compilation units. Other combinations such as 2, 4, 8, 16, or 32 kernels per OpenCL program are also considered in this benchmark (always adding up to a total of 64 kernels).
For comparison we select the recent OpenCL SDKs from the major vendors:
The benchmark is run on an OpenSUSE 13.2 machine with an AMD FirePro W9100 GPU to measure jit-compilation overhead for an AMD GPU. All other benchmarks are taken on a Linux Mint Maya machine with an AMD A10-5800K APU equipped with a discrete NVIDIA GeForce GTX 750 Ti GPU. The CPUs on the two machines are comparable: The deviation of the jit-compilation targeting the CPU with the AMD OpenCL SDK is below ten percent. Unfortunately, a suitable Intel GPU was not available for measuring the jit-overhead of the Intel OpenCL SDK when targeting GPUs.
The OpenCL JIT compilation benchmark source code and results are available for download and should answer any remaining questions on details.
Benchmark Results
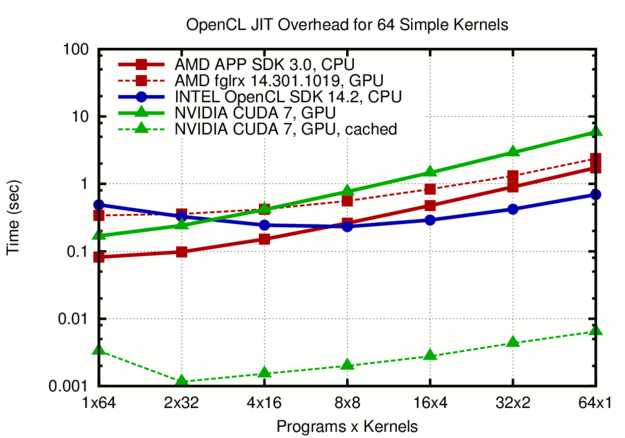
Time required for the just-in-time compilation of 64 simple OpenCL kernels. Overall, it is better to pack all kernels into two to four OpenCL programs rather than compiling all kernels in individual programs.
As the figure above shows, the rule of thumb for jit compilation overhead is 0.1 to 1 second, with slight deviations between the three vendors and the target device. A common trend is that compiling each kernel individually in a separate OpenCL program is worst in terms of overhead: It took more than 5 seconds to compile the 64 kernels for the NVIDIA GPU.
The 5 seconds overhead for the compilation of the 64 kernels for NVIDIA GPUs are only encountered at the first run. From the second run onwards, the compiled binaries are taken from the cache (more details on jit caching here), reducing the 'experienced' overhead dramatically from a few seconds to a few milliseconds. I hope that AMD and Intel will provide a similar jit caching mechanism soon, because a few seconds of kernel compilation cannot be considered 'short' for many applications. Otherwise, OpenCL-enabled libraries are forced to implement their own caching functionality, resulting in unnecessary code duplication across the community.
Conclusions
When dealing with OpenCL, one has to think about granularity. It is tempting to compile one kernel after another inside a library or an application (think about expression templates in C++ here!). However, this is almost certain to maximize the jit-overhead. Kernel caching reduces the overhead by three orders of magnitude on a desktop machine, but this may be no longer true on a supercomputer with a relatively slow network file system. A user may set the cache path to a local folder (e.g. /tmp) as a workaround, but most users may not be aware of that option. Thus, despite of the headache one can get with NVIDIA's CUDA toolchain on non-standard environments, one has to admit that they have circumvented the problem of jit-compilation with their CUDA compiler toolchain. SyCL might achieve the same in the OpenCL world, but this has yet to be proven.
This blog post is for calendar week 2 of my weekly blogging series for 2016.